I translated a Chinese dictionary from English. Here are 5 takeaways for the translation industry.
This article originally appeared in Jost Zetzsche's 302nd Tool Box Journal on July 7, 2019.

Five years ago I discovered a much-needed gap in the world: there was a tragic shortage of open Chinese-Hungarian dictionaries on the Internet. I soon decided that it was my mission to fill this gap.
There was one small problem I had to overcome to do this. I don’t really speak Chinese.
Here is, then, what I learned about the translation industry as I created CHDICT,[1] the world’s first open-source, collaboratively edited Chinese-Hungarian dictionary.
Wait... what is CHDICT?
It is any and all of the following:
- A downloadable text file with an open public license where each line contains one Chinese word and its senses in Hungarian
- A website where you can look up Chinese or Hungarian words, or find the meaning of hand-drawn Chinese characters
- The translation into Hungarian of the English senses in CC-CEDICT, an established Chinese-English dictionary
- An online collaboration space where people add, improve and correct dictionary entries
I seeded CHDICT between February 2015 and May 2017 with about 11 thousand entries. The main approach in this initial phase was the translation of the English part of CC-CEDICT, focusing on the most frequent Chinese words, plus those less frequent ones that are included in the PRC’s official language examinations.
Afterwards, I used machine learning to extract bilingual vocabulary from 3 million Chinese-Hungarian movie subtitle pairs. This way, I was able to manually review and add another 4 thousand entries to CHDICT in only a few months. Over the same period, CHDICT began to attract contributors, who added or amended hundreds of entries on their own.
Deriving dictionaries for niche language combinations is a nice hobby for some; but I want to use this opportunity to share the insights I’ve gained during the process about professional translation more broadly.
1: Everything you translate is another translator’s input
A dictionary is typically an input that you use as a translator, and not the output of your work. When you translate a dictionary, then, that turns everything upside down.
Yet as I thought more about this, I realized that most of our output as translators is a direct input into the work of other translators. That’s clearly the case when you build a shared glossary. But even when you just commit segments into a TM, you are growing a resource that another translator will probably use later. From this angle, translating a dictionary no longer seems particularly special.
And here’s the thing: every translation that is ever stored digitally will eventually be vacuumed up by a machine translation (MT) engine. Certainly that will happen to every piece of content published on the Internet; but rest assured, even highly confidential internal-use-only texts will find their way into the inner parameter space of a highly confidential, internal-use-only MT engine.
2: Clarity about IP and copyright is super important
I could not have done CHDICT, or at least not done it this way, were it not for CC-CEDICT’s public license. Intriguingly, that license was not always in place. CEDICT operated without any explicit license until 2007, when the person running the project simply disappeared. That was a really tough spot to be in for the people who wanted to carry on the torch! Things were eventually sorted out, and the dictionary added „CC” to highlight the now-official Creative Commons license.
But what sort of intellectual property (IP) is a dictionary? Language is a common good; nobody owns the words in its lexicon. Think of it like this: nobody owns gravity, but the physicist who writes a book about gravity does own the book’s IP.
While modern dictionary-making has always been a commercial enterprise in the UK and the US, it is typically an academic pursuit elsewhere. In both cases, it’s clear the dictionary stands as a work on its own, and its IP is jealously guarded by the holders of private licenses.
What is the IP in the case of a translation, whether it’s that of a dictionary, or any other content? It’s the translation industry’s major debt that we never properly resolved this. The active conversation from 10-15 years ago simply subsided. And now that it’s become clear that every translation is somebody else’s input, we’re in a situation where MT services can serve millions of translation requests a day and not pay a cent to the creators of the sentence pairs that the engines are trained on.
2b: A public license is the best guarantee for a work’s survival in the digital age
Before the digital revolution, humanity’s knowledge was stored in libraries in the form of physical books. Today, humanity’s knowledge is stored digitally, online.
Online digital content has very different survival patterns from printed books. If you stop maintaining your server, the content is gone; think link rot. On the other hand, copies long outlive the original; think Google never forgets. The best strategy for the long-time survival of any digital work, then, is a copy-free public license.
If I get run over by a bus, replicas of CHDICT’s data file will still be stored in many places, and eventually someone else will revive the project and re-publish the dictionary.
Contrast that with the thousands of out-of-print books that the publisher has no incentive to re-print. Or with a non-public digital work whose copyright holder gets run over by a bus.
I witnessed a unicorn kind of event while working on CHDICT: the open-sourcing of Taiwan’s “official” Chinese dictionary, MOEDICT.[2] That came out of the 2014 Sunflower Movement. Urged by the students occupying Parliament, the government created a digital ministry, appointed an anarchist hacker[3] to lead it, and started accommodating regular “gov0” hackathons. One of these hackathons looked at MOEDICT, convinced the officials that it was a public good, and published it under an open license. Don’t tell me dictionaries are boring stuff!
3: Linguists will become NLP wizards (also, translation defined)
OK, I’m obviously a geek, and one obsessed with CAT tools at that. I coded my own DTE™ (Dictionary Translation Environment) to make translating CC-CEDICT entries really, really efficient. It looks like this:
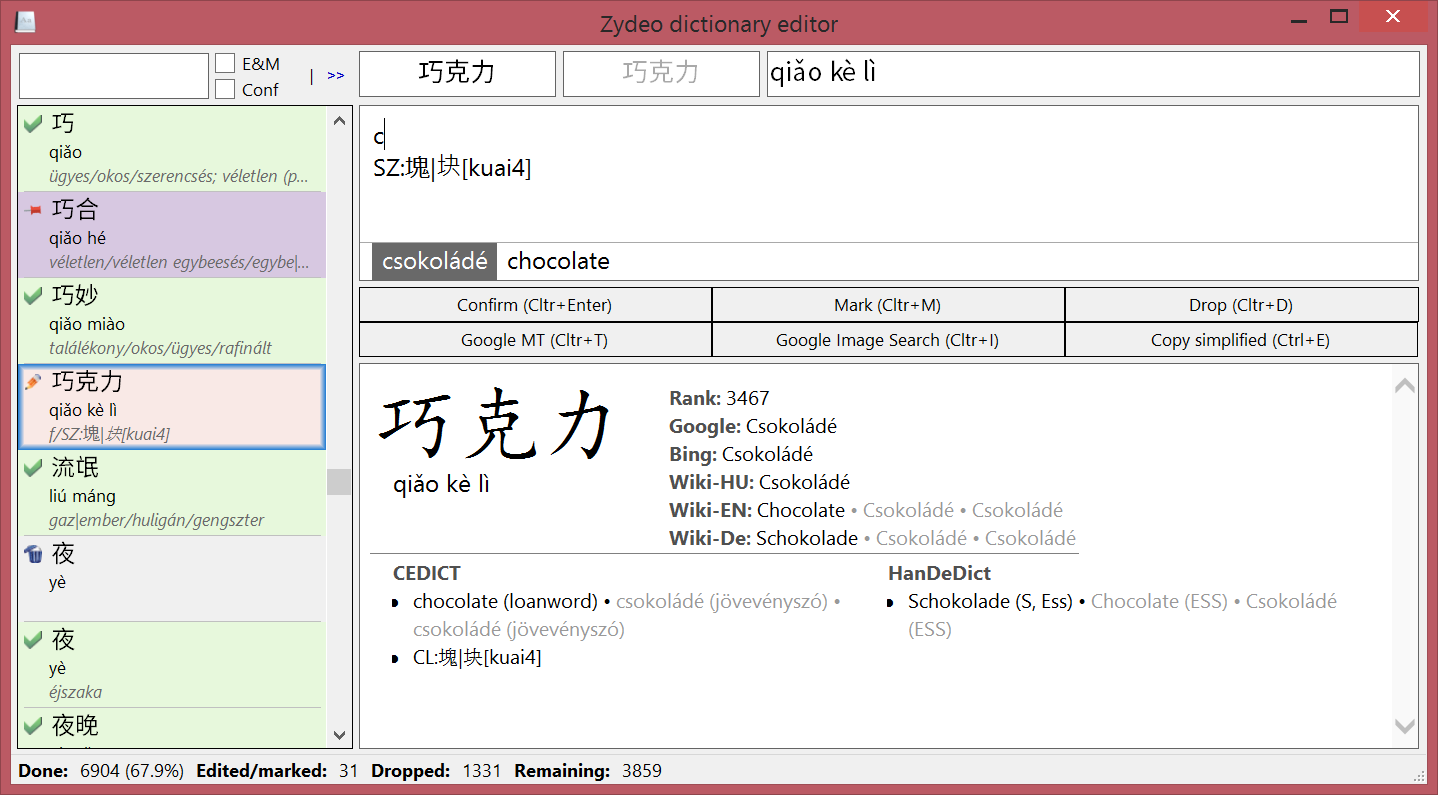
The functionality is slightly different from a regular CAT tool, but yes, the goal is to make all the items on the left turn green, and yes, the shortcut to confirm an entry is Ctrl+Enter.
I’m not suggesting that linguists will all be coding their own CAT tools in the future. But the real underlying work about CHDICT, particularly in the second phase, was about mobilizing natural language processing (NLP) techniques to tease lexical information out of heaps of bilingual and even monolingual data. The details would be tedious here, but I wrote an article about it that won best paper award at MSZNY 2018; if you’re really into this stuff, I included the PDF among the references.[4]
You see my situation was, I only knew my domain (the Chinese lexicon) superficially, so I had to do lots of research to understand what my source words meant. That’s not unlike what happens in a normal translation setting. At the outset, we’re not experts in the domain of a particular text, and we do research to make sure we get it right. Then, we reproduce the text’s message and intent in the target language; and between us, we have a really, really good command of that target language. Translation = Research + Mastery of the Target Language.
NLP gives you superpowers for the research part. It’s your brain augmented to access the information encoded in a millions of segment pairs, and more. Actual understanding, and artful expression, are the human privilege in the mix.
4: Tools encode the social dynamics of collaboration
You would normally think of a dictionary’s users as those who look up words in it. But because CHDICT is a collaborative, open dictionary, the smaller number of users who add to it and edit it are equally important.
How that contribution and collaboration happens is directly driven by the website. English Wikipedia is a free-for-all: anyone can make an edit with a single click, and the change is immediately published. This apparently works with a very, very large pool of contributors.
CC-CEDICT, by contrast, uses a pretty rigid process: registered users can submit edits and new entries. These get queued up, and they only go live if someone from a small, closed circle of reviewers processes it. This seems to work fine for CC-CEDICT, although the dictionary’s been getting less activity[5] in recent years.
For CHDICT, I knew I could count on a much smaller pool of contributors. So I chose not to add many obstacles before someone could start contributing, but still include a mechanism that drives changes through a four-eyes review process for quality.
The meta-story here is that the forms of engagement, authority, power relations, and overall social dynamics are all coded into the tools we use to collaborate. Since translation has become a fully collaborative online process, that gives tools an immense power to shape the industry’s dynamics. Tool makers are well advised to wield this power wisely and ethically.
5: Some of the best things don’t have a business model
CHDICT has been online for about 2.5 years now; I have a pretty good idea about its usage statistics. It has over 100 monthly users who spend an average of 20 minutes on the site for each visit; roughly 2000 words are looked up each week.
These figures are in line with my original expectations, which I based on the usage statistics of the Chinese-German dictionary HanDeDict, and on a rough estimate of people professionally interested in Chinese in a population of under 10 million.
These are also figures that constitute approximately €0.00 monetizable value. And that is fine with me. Most of the best things in life do not come with a viable business model. I only wish that as a society we figured out a way to better compensate, in particular, amazing translators of truly complex texts. I mean the likes of Emily Wilson or Ken Liu, but also the hundreds of highly skilled people who translate valuable works that do not make it to the bestseller lists.
References
[3] She's 唐鳳 (Audrey Tang). You can find her on Twitter @audreyt.
[4] Gábor Ugray: Etudes in Chinese-Hungarian Corpus-Based Lexical Acquisition. 15th Conference on Hungarian Computational Linguistics, January 18-19, 2018, Szeged, Hungary. [PDF]
[5] CC-CEDICT contributions follow Zipf’s law
aka-gabor.xyz/texts/cc-cedict-contributions-zipfs-law/